

ニッセイアセットマネジメント版生成AIチャット活用コンテストを開催しました。~②面白いアイデアがたくさん集まりました~

当社では、ChatGPTを始めとした「言語生成AI(ChatGPT)」や「LLM(Large Language Model:大規模言語モデル)」の活用に積極的に取り組んでおり、今年の8月にセキュアな環境で利用できるニッセイアセットマネジメント版生成AIチャットをリリースし、社内で利用しております。
前回、①開催概要編 では、今年の9月8日から10月26日までの約2ヶ月間実施した『第3回DXブートキャンプ(生成AIチャット活用コンテスト)』の概要や運営のポイントについてご紹介しました。
今回は、本コンテストで応募された活用アイデア・ソリューションについて、技術的な面も含めてご紹介します。
生成AIチャット・LLMの活用アイデア・ソリューションについて、2種類の方式に分類することができます。
1.社内独自データをインプットとし、加工されたものをアウトプットとする方式[RAG方式]
やはり社内業務を中心としたコンテストなので、社内データやウェブサイトから取得したPDFファイル等を利用したいというアイデア・ソリューションが多く、応募数の9割近くにのぼりました。
いわゆるRAG(Retrieval Augmented Generation)という方式を利用して実現するものです。

※RAGやベクトルDBについては、こちらに詳しく記載されています。
2.インプットデータは特になく、生成AIチャットが考えた結果をアウトプットとする方式
お客様のペルソナを設定し、訴求的なお客様向けメール案を生成したり、SNSへの投稿内容案を生成してもらうといったアイデアです。こちらは特に外部パッケージを使うことなく、生成AIチャットの画面にプロンプトを打ち込むだけの単純なものですが、それだけにプロンプトエンジニアリングの奥深さを感じます。
今回は、1.の[RAG方式]で応募されたソリューションをいくつかご紹介します。
1.新規参画者向け研修bot
多くの会社で、新規参画者(新入社員や中途入社社員)の受け入れ時研修を行っていると思います。
みなさんの会社では、どのような研修が行われていますか?
資料を配って対面で説明でしょうか。それともオンラインで集合研修でしょうか。
当社の一部の部署では、専用のドキュメント(Googleスプレッドシート)を用意し、研修担当者が数日かけて新規参加者に様々な内容を研修しています。
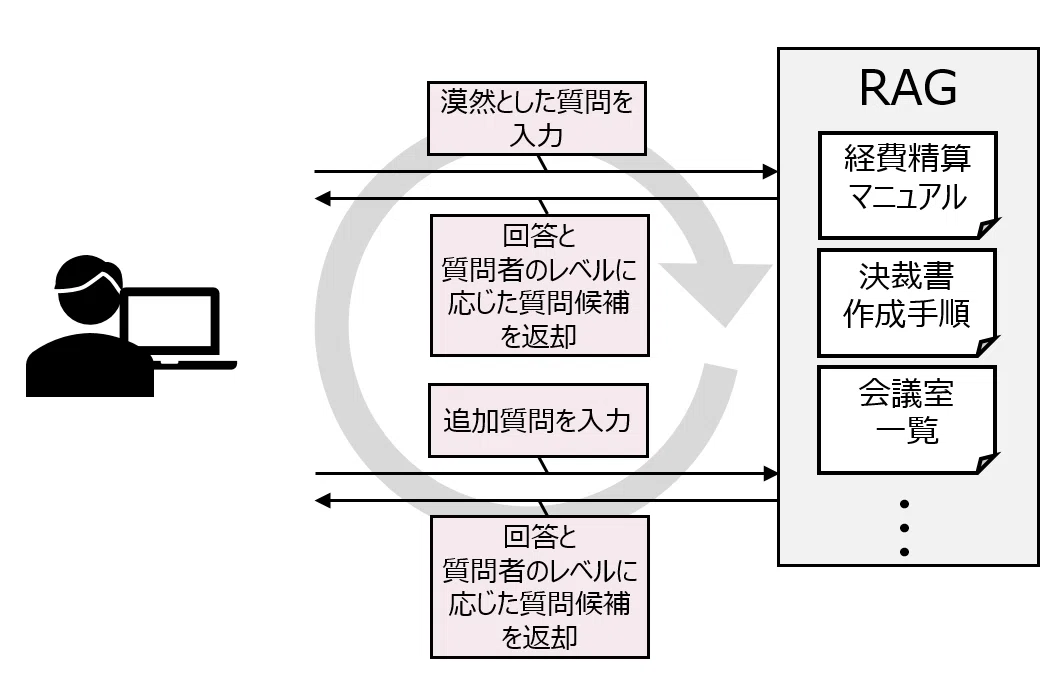
経費精算の方法、決裁書の書き方、会議室の予約の仕方など、非常に細かい内容ですが、仕事をするうえではとても重要な内容を教える必要があります。
それぞれの手続きに関する細かいマニュアルは存在していますが、内容を初心者にわかりやすく説明しているドキュメントは少なく、研修担当者が前述の専用ドキュメントを更新したり、口頭で説明したりしています。また、情報の更新頻度も高く、準備にも結構な時間とセンスが必要となる、なかなか骨の折れる業務になっています。
そこで、研修担当者が「生成AIチャットやLLMを活用して何とかしたい」と考え、コンテストに応募してくれました。
個別の業務ごとにマニュアルを整備するのは大変
言語生成AI(ChatGPT)・LLMを活用するメリットの一つとして、回答に高い精度を求めないのであれば、データの源泉となるドキュメントを整備しなくても、それなりの回答をしてくれる点にあると思います。
言語生成AI(ChatGPT)・LLMを活用しない環境でデータベースを整備しようとすると、まずインプットデータをデータベースのフォーマットに合わせて整備、適切なインデックスを用意し、フロントのアプリケーションから呼び出す仕組みを構築し・・・と、それなりのシステム開発が必要になるでしょう。
また、言語生成AI(ChatGPT)やLLMを活用したとしても、「漠然とした内容」を「精密な内容」に昇華させるには、few-shot-learningやOn your dataを駆使して源泉を整備しつつ、fine tuningする必要があり、手間がかかります。
このように、言語生成AI(ChatGPT)やLLMの得意分野不得意分野を自分なりに整理しておくことは、業務への利活用を検討する際に「筋の良い」アイデア・ソリューションを発掘するために、とても大切な視点となります。「詳細なマニュアルはあるけど、初心者にわかりやすくかみ砕いたドキュメントがない」という今回の課題は、「筋が良い」と考えました。
セルフラーニングできる仕掛け
ここでは、簡単なフロー図と、実際のpythonコードの一部をご紹介します。pythonではOpenAI・LLM関連で有名なライブラリ・フレームワークであるlangchainを活用して実現しています。
from langchain import PromptTemplate
from langchain.llms import OpenAI
#プロンプトテンプレートの設定
template = """Use the following pieces of context to answer the question at the end.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
Use three sentences maximum and keep the answer as concise as possible.
{context}
Question: {question}
Helpful Answer:"""
prompt = ChatPromptTemplate.from_template(template)
question = "交通費の精算手続きを教えてください?"#キーワードを指定
query = question + "質問者に適した追加質問候補を、回答の最後に3つ追加してください。"
embedding_vector = embeddings.embed_query(query)
docs_and_scores = db_pages.similarity_search_by_vector(embedding_vector)
# load_qa_chainを準備
chain = load_qa_chain(
AzureOpenAI(model_kwargs={'engine':'gpt-35-turbo'},temperature=0),
chain_type="stuff",
prompt=prompt
)
# 質問応答の実行
answer = (chain({"input_documents": docs_and_scores, "question": query}, return_only_outputs=True))
answer_text =str(answer).replace('output_text','').replace('\n','')
print(answer_text)
#回答 {'': ' 交通費の精算手続きは■■を使って行います。■■のPWは入社時にメールで送られてきています。精算の手順は以下の通りです。1. ■■にログインし、新規申請をクリックする。2. 交通費の項目を選択し、必要事項を入力する。3. 領収書を添付する。追加質問候補:■■のPWを忘れた場合はどうすればいいですか?■■で交通費以外の精算もできますか?■■での精算手続きはどのように進めればいいですか?\n<|im_end|>'}※apikeyやendpointの設定は省略します。
回答としては、大分ざっくりしていますが、新規参画者が入社後数日以内に知るべき内容としては、これくらいのレベルでいいのではないでしょうか。
ここでのポイントは、図2にあるように、セルフラーニングを促すために、RAG(生成AIチャット)が追加質問候補を提示してあげるという仕組みです。実際のコードでもqueryの箇所に「質問者に適した追加質問候補を、回答の最後に3つ追加してください。」というプロンプトを追加しています。
また、Prompt Templateにgptに期待する振る舞いをデフォルトで指定しておくのがおすすめです。今回は、「知らないことは正直に知らないと言ってね」というような指定をしています。
2.法人向け営業サポートツール
当社では、企業年金のお客様向けのサービスを、対面・オンラインの両面で展開しております。
オンラインでは「NAVIS」というウェブ上で様々なレポートを配信するサービスの運営を行っており、おかげ様で大変多くのお客様にアクセスしていただいたいております。
本アイデア・ソリューションは、お客様が「NAVIS」でアクセスしたレポートや、対面で直接ヒアリングしたお客様の課題に関するレポートをベクトルデータとして読み込み、読み込んだDBと営業担当者が対話することによって、お客様の課題をより深く理解しつつ、営業活動のレベルアップを目指すものです。
文書の類似性を数値化することにより、定性的判断を定量的判断へ
突然ですが、あなたが銀行や証券会社の営業担当者だったとして、お客様に「株式投資にリスクを感じている」と言われたら、次にどの商品を提案しますか?
金融機関に勤務した経験のある方でしたら、多くの方は「債券投資」と答えるのではないでしょうか。一般的に「株式」と「債券」の値動きが「負の相関」となる(そうならないことも多いが)ことについて知っていたり、実際にお客様と対話した経験上、そのように感じる方も多いかもしれません。
言語生成AI(ChatGPT)やLLMでは、これらの「定性的」な判断を、”類似性”という数値を使うことによって可視化し、「定量的」な判断へ変換できる可能性があると感じています。
ポイントは「similarity_search_with_score」
import numpy as np
import pandas as pd
import re
# embeddings APIを呼ぶ準備
embeddings = OpenAIEmbeddings()
t_Id = 'All'
db_pages = FAISS.load_local(f"faiss_index_navis_{t_Id}", embeddings)
df_simil = pd.DataFrame()
query = 'ヘッジ外債について'#キーワードを指定
results = db_pages.similarity_search_with_score(
query, # 入力クエリ
k=10, # 指定した数だけ検索結果を抽出
)
df=pd.DataFrame()
for i in range(len(results)):
list_=[[results[i][0],results[i][0].metadata["source"],results[i][1]]]
df_new = pd.DataFrame(list_,columns = ['content','source','score'])
df = pd.concat([df,df_new])
for i in results:
result, score = i
print({"score": score, "content": result.page_content[0:30], "metadata": result.metadata} )
#回答 {'score': 0.2586872, 'content': '5\uf06eヘッジ外債の運用悪化は、最初は金利上昇によるキャピタルロ', 'metadata': {'source': 'C:\\Users\\yamada_t890\\Documents\\navis_pdf\\202309\\【年金運用サポート情報No.2】米金融引締め最終局面での債券の戦略構成を考える.pdf', 'page': 4}}
{'score': 0.26624447, 'content': '13◼政策ベンチマーク対比で超過収益獲得が期待されるヘッジ外', 'metadata': {'source': 'C:\\Users\\yamada_t890\\Documents\\navis_pdf\\202309\\【資産クラスNo.75別冊】野村薫の“国内債券どないしよ”~債券市場の変化と国内債券ポートフォリオの再考~.pdf', 'page': 12}}
{'score': 0.26864806, 'content': '6とある討論会の場面~「なぜ、マイナスゾーンに沈むヘッジ W', 'metadata': {'source': 'C:\\Users\\yamada_t890\\Documents\\navis_pdf\\202309\\【年金運用サポート情報No.2】米金融引締め最終局面での債券の戦略構成を考える.pdf', 'page': 5}}
{'score': 0.29328394,・・・※apikeyやendpointの設定は省略します。
指定した文章(ここでは「ヘッジ外債について」)と、読み込んだベクトルDB内の文書との、ベクトルの距離を数値化し、scoreとして算出しています。数値が小さい方が近い、すなわち「類似性が高い」ことを意味しています(厳密には、コサイン類似度やユークリッド距離など、距離の計測方法によって評価方法が異なりますが、ここでは省略します)。
数値化できれば、先ほど例にあった「株式」と「債券」の関係のように、担当者の知識・経験上“遠い位置にある”と理解している商品についても、数値として実際にどれだけ距離が離れているのか確認することができますし、知識・経験上判断しにくい、より複雑な課題やテーマについても可視化し、お客様に、より最適な提案やサポートができるようになるかもしれません。
まとめ
本記事でご紹介したもの以外にも、非常に面白い、業務に役立つアイデア・ソリューションがたくさん集まりました。
特に運営チームが驚いたのは、「ほとんどのアイデア・ソリューションが重複しなかった」というところです。
50名近い参加者がいるなかで、2~3割程度は重複すると想定していたのですが、ふたを開けてみると、多くの参加者の方が、言語生成AI(ChatGPT)やLLMの活用について真剣に考え、結果として他と重複することなく、オリジナリティあふれるアイデア・ソリューションが多く集まりました。
今後も定期的にイベントの開催を続けていきたいと思います。
※本記事内でご紹介しているイベント「DXブートキャンプ」の運営やコンテストの内容などについてより詳しく知りたい方は、「クリエイターへのお問い合わせ(https://note.com/nissayasset/message)」より、お気軽にご連絡ください。
【筆者紹介】
山田智久:大手証券会社入社後、ネット銀行立ち上げを経て、大手小売業にて複数の大型DXプロジェクトに従事。2022年よりニッセイアセットマネジメントにて資産運用に関するDX業務を担当。CFP🄬認定者。UX検定™保有。
・当資料で、筆者の紹介のある記事においては、掲載されている感想や評価はあくまでも筆者自身のものであり、ニッセイアセットマネジメントのものではありませんが、ニッセイアセットマネジメントと筆者との間でこれらの表示に係る情報等のやり取りを直接的又は間接的に行っているため、実質的にはニッセイアセットマネジメントの広告(「不当景品類及び不当表示防止法」におけるニッセイアセットマネジメントの表示)等に該当する場合がございますので、ご留意願います。